Controller (控制器) 在 Kubernetes 中是逻辑能力的主要体现所在,根据资源对象的状态来完成调和工作,让资源对象逐步接近期待的状态,这个就是 Kubernetes 的申明式特性。
在 Karmada 中,同样需要对 Karmada 自己的资源对象,实现对应的申明式特性,这就需要实现对应的 Controller。在Karmada 中目前的版本中有 11 个 Controllers,接下来就从每一个控制器所负责的资源对象,以及原理来分析一下,在 Karmada 中是怎样完成多云能力的。
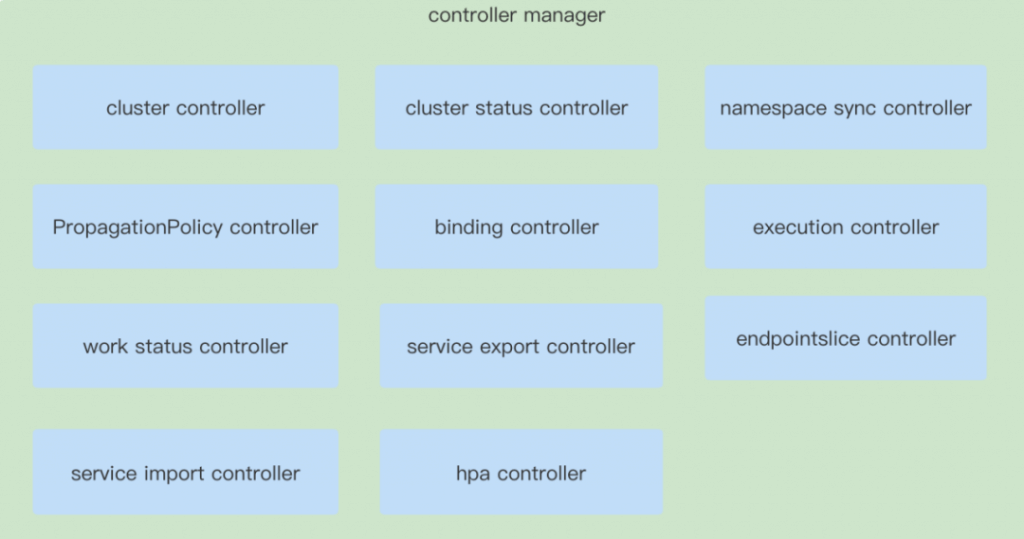

Cluster Controller
cluster controller 主要就是处理 Cluster 资源对象的逻辑,负责处理 Cluster 对应需要的关联资源。
相关资源对象:Cluster
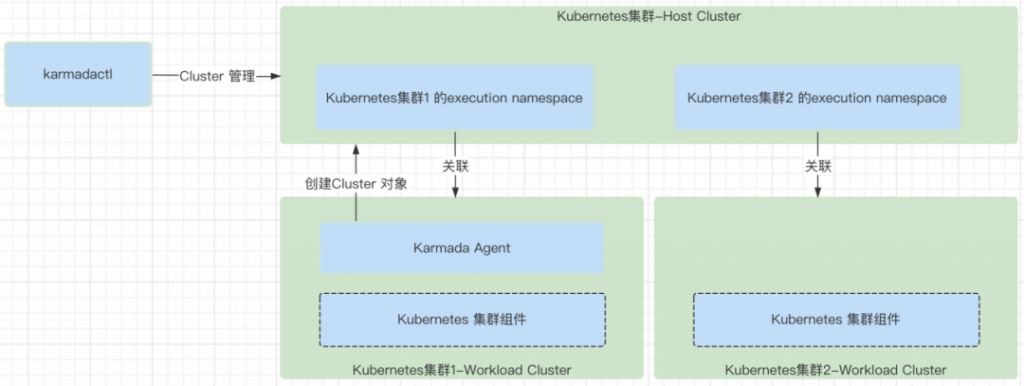
- 创建 Cluster 的时候,需要在 Karmada 中创建对应的 execution namespace,这个 namespace 中会保存所有这个集群相关的 Work 对象。
- 删除Cluster的时候,需要在 Karmada 中删除对应的execution namespace。
- Cluster 资源对象保存在 karmada-cluster 这个 namespace 中,这个 namespace 中保存了所有集群对应的 Cluster 资源对象。
Cluster status controller
cluster status controller 主要就是处理 cluster status 资源对象的逻辑,用来收集 Cluster 的状态,保存到 Cluster 的 status 字段中,同步上报到 Karmada 的控制平面中。
相关资源对象:Cluster
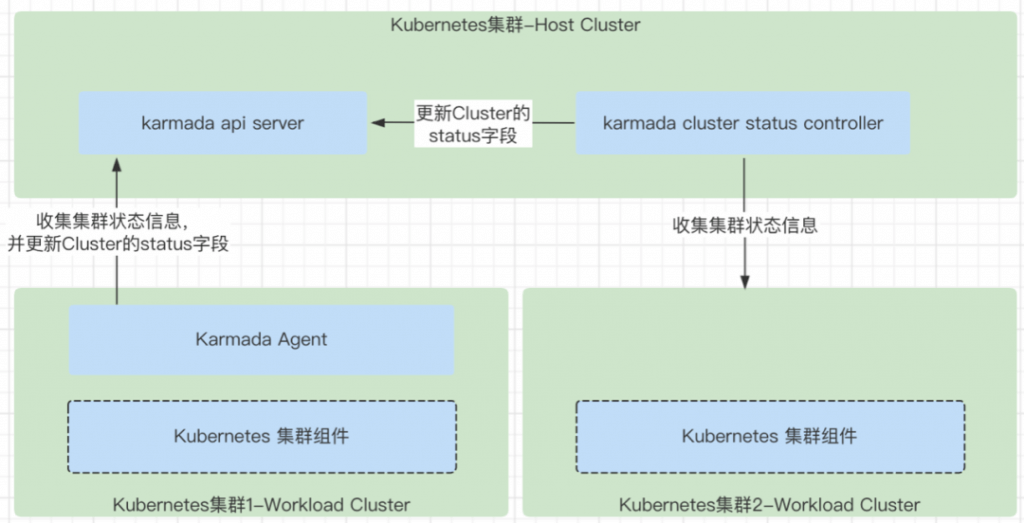
- watch Cluster 对象,然后执行 sync 方法,同步上报集群的状态给Karmada 控制平面 (也就是 Karmada 集群中,karmada-cluster 这个 namespace 中的某一个 cluster 对象)。
- 收集当前 agent 所在集群的状态信息,这些信息包含 Nodes 统计,Pods 相关的资源统计,Kubernetes 版本,以及 Kubernetes 集群支持的资源对象的类型的 GVR,其中包含 CRD 的支持信息等,然后同步更新到 Karmada 控制平面 Cluster 对象的 status 中。
namespace sync controller
namespace sync controller 主要就是处理 namespace 资源对象的逻辑,负责将 Karmada 控制平面创建的 namespace 在集群中同步创建出来。
相关资源对象:namespace

- namespace sync controller 就是为了将在 Karmada 中创建的 namespace 在所有的工作集群中也去创建出来。
- namespace 是 “karmada-cluster”,或者是 “karmada-system”,或者是 “default”, 或者 namespace 是 “karmada-es-<xxx>”, 或者是 “kube-<xxx>” 这样 namespace 是不需要处理的。以及被包含在 SkippedPropagatingNamespaces 配置中的 namespace,也不需要处理。
Resourse Template controller
detector 模块中包含了通用 controller 负责 resource template 的 Kubernetes 资源对象的调和处理逻辑,以及匹配 PropagationPolicy。主要就是处理 PropagationPolicy 资源对象的逻辑,来派生出资源对象对应的 ResourceBinding 对象。
相关资源对象:PropagationPolicy, Kubernetes 支持的所有的资源对象 (包括 CRD)
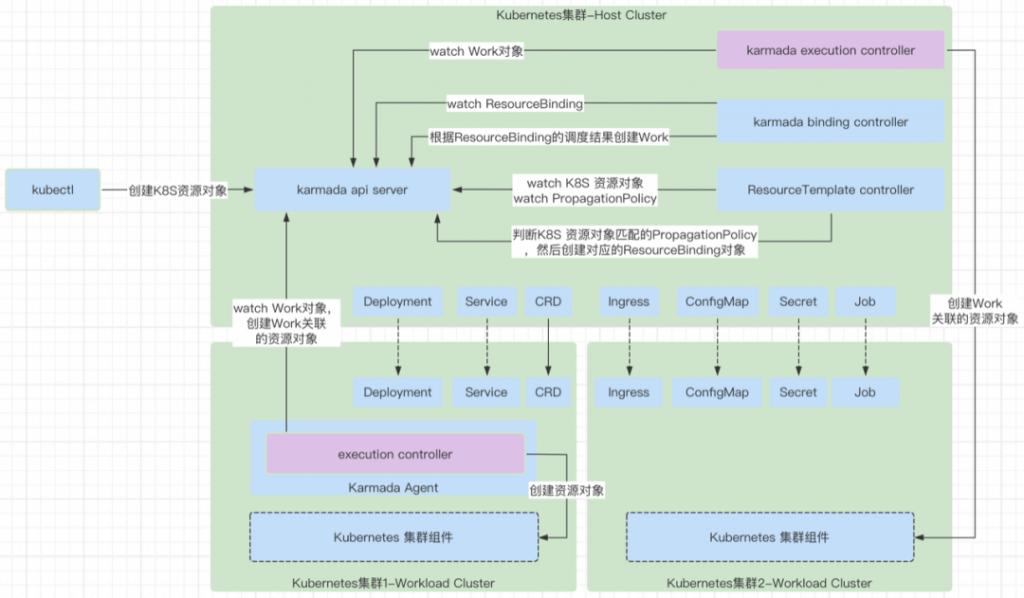
- 定义处理 PropagationPolicy / ClusterPropagationPolicy 的 informer,event handler,以及对应的 reconciler 方法。
- 定义处理 ResourceBinding / ClusterResourceBinding 的 informer,event handler,以及对应的 reconciler 方法。
- 定义处理所有原生 Kubernetes 资源对象的 informer,event handler,以及对应的 reconciler 方法,然后为其创建对应的 ResourceBinding 对象用于调度。
- 根据 Kubernetes 的对象定义以及 PropagationPolicy 构建 ResourceBinding 对象,同时这个 ResourceBinding 的 OwnerReferences 设置了这个 Kubernetes 的对象,这样就会在删除 Kubernetes 对象的时候删除这个 ResourceBinding,这个也是目前 ResourceBinding 会被删除的唯一逻辑了。
- 所以虽然 ResourceBinding 是因为 PropagationPolicy 的创建而被派生出来,但是不会因为 PropagationPolicy 的删除而删除。
- 在删除 PropagationPolicy 删除的时候,只会去除 PropagationPolicy 和 Kubernetes 对象的关系,这个关系体现在,Kubernetes object 会在匹配到 PropagationPolicy 的时候在自己的 label 上增加 PropagationPolicy 相关的 label。
- ResourceBinding 中不会包含 Kubernetes 资源对象的详细信息,只会包含类型,namespace,name,版本,副本数,cpu/memory 请求,节点亲和性,真正详细的 Kubernetes 对象的处理是在 controller 的syncbinding() 方法中完成,其中是通过workload, err := helper.FetchWorkload (c.DynamicClient,c.InformerManager,c.RESTMapper, binding.Spec.Resource) 去拿到真正的 Kubernetes 资源对象的定义的。
- 每隔 30s 去发现新的 Kubernetes 的资源对象类型,只要这些资源对象支持 list,watch,delete 方法,当然也包括 crd 类型。
Binding controller
binding controller 主要就是处理 ResourceBinding 资源对象的增删改逻辑,ResourceBinding 的调和能力是派生出 work 对象,work 对象是和特定集群关联的。一个 work 只能属于一个集群,代表一个集群的资源对象的模型封装。
相关资源对象:ResourceBinding 和 ClusterResourceBinding
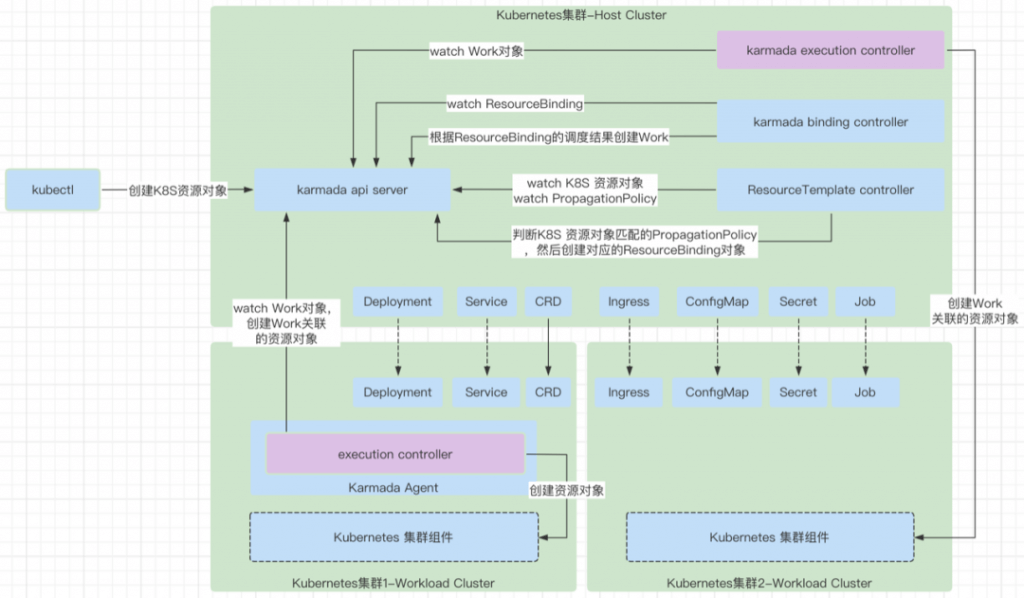
- 负责 ResourceBinding 的处理,根据 binding 去创建对应的 Work 对象到集群对应的 execution space 中。
- 在生成 Work 的时候,会处理 OverridePolicy,将需要覆盖的数据更新到 Work 对应的 manifest 中。目前支持的 override 的方式主要是 4 种,包括:PlaintextOverrider,mageOverrider,CommandOverrider,ArgsOverrider。
apiVersion: policy.karmada.io/v1alpha1
kind: OverridePolicy
metadata:
name: nginx-propagation
spec:
resourceselectors:
一 apiVersion: apps/v1
kind: Deployment name: nginx
targetcluster:
clusterNames:
-10-23-20-93
overriders:
plaintext:
一 path: "/spec/template/spec/containers/O/image"
operator: replace value: "nginx:test"- 根据调度器计算好的每一个集群负责的副本数,如果调度器计算出来的所有集群的对应的副本数是 0,说明没有找合适的集群,就用 ReplicaSchedulingPolicy 根据权重去计算每一个集群应该负责的副本数,这个 ReplicaSchedulingPolicy 的计算副本分配的方式是用 static weight。
- 收集每一个 binding 的状态,一个 binding 会包含多个 Work,因为同一个资源对象,在每一个集群中就需要一个 Work,所有 binding 的状态是所有工作集群中 Work 的状态的汇总,汇总之后将这个状态设置到 binding 的 status 中去。
execution controller
execution controller 主要就是处理 Work 资源对象的增删改逻辑,用于处理 Work,将 Work 负责的 Kubernetes 资源对象在对应的集群上创建出来。
相关资源对象:Work
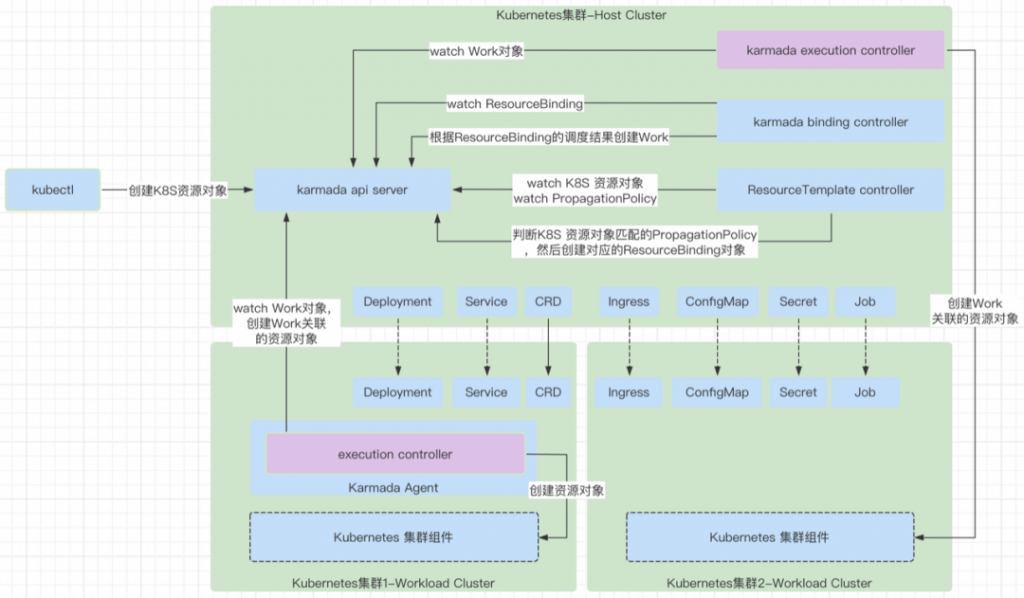
- watch Karmada 控制平面的 execution namespace 中的所有 Work 对象,当有新的 Work 对象被创建了之后会在对应的工作集群中创建 Work 负责的资源对象。
- watch Karmada 控制平面的 execution namespace 中的所有 Work 对象,当有 Work 对象被删除的时候,会在工作集群中,删除 Work 对象负责的资源对象。watch Karmada 控制平面的 execution namespace 中的所有 Work 对象,当有 Work 对象被修改了之后,会在工作集群中,修改 Work 对象负责的资源对象。
work status controller
work status controller 主要就是处理 Work 资源对象的状态逻辑,负责收集 Work 的状态,也就是 Work 对应的资源对象的状态,只是这个状态是保存在 Work 的 status 字段里的。
相关资源对象:Work,以及 Work 负责的资源对象。
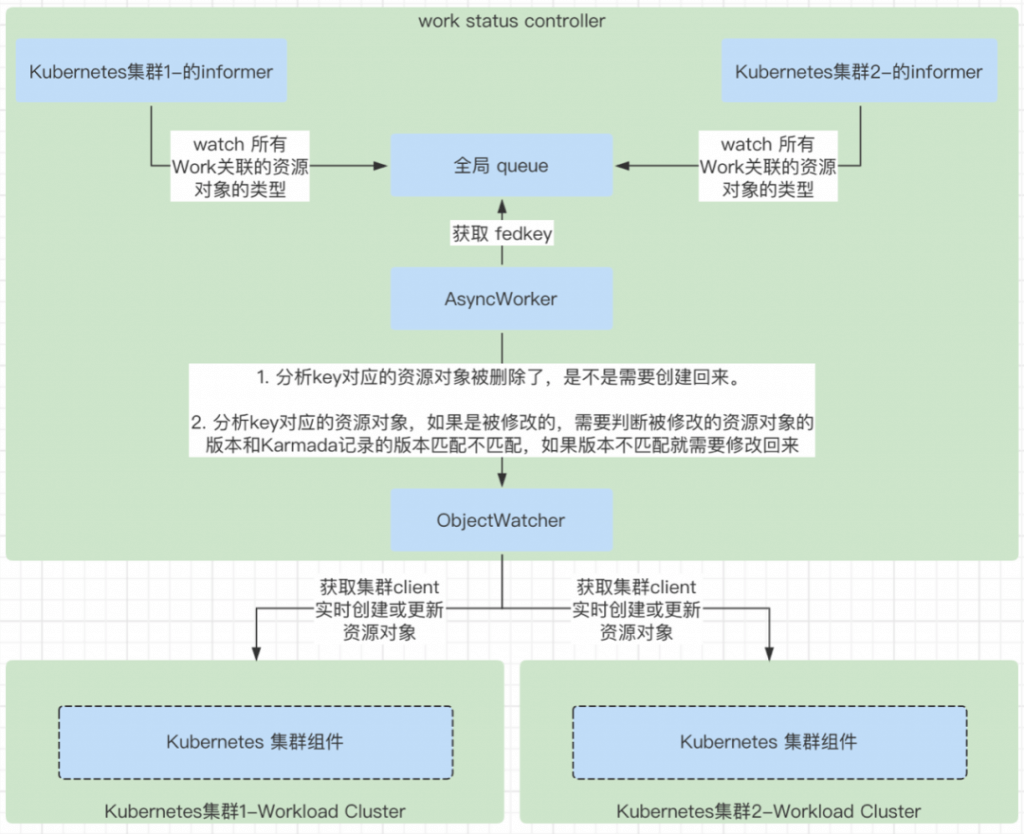
- watch Work 对象为指定计算集群包含的所有的 Work 对象所负责的资源对象的类型创建对应的 informer 对象,同时调用 informer 的 WaitForCacheSync,当 WaitForCacheSync 结束了之后,也就是 list 结束了,接下来就是 watch 的任务了。这个就是 list and watch 的核心机制。
- 在 watch 所有 Work 负责的资源对象的时候,设置了一个事件处理器,这个事情处理器会负责处理所有相关资源对象的 Add,Update,Delete 事件。这些事件存放在 queue 中。
- 启动一个异步的 AsyncWorker, 设置一定的 WorkerNumber 数量的 goroutines 去处理 queue 里的数据,这里的数据是带有集群信息的 fedkey。
- 从 queue 中获取 fedkey,判断这个 fedkey 的对应的集群中的资源对象,如果这个 Work 负责的资源对象在工作集群中被非法删除了,会重新在工作集群中创建出对应的资源对象。
- 从 queue 中获取 fedkey,判断这个 fedkey 的对应的集群中的资源对象,如果这个 Work 负责的资源对象被修改了之后是不是修改被修改回去。如果是的话,会重新 sync 回资源对象,防止直接从工作集群中直接修改资源对象。
- 收集 Work 对象对应的资源对象在 Worload 集群中的运行状态,然后更新到到控制平面的 Work 的 status 中。
- watch Karmada 控制平面的 execution namespace 中的所有 Work 对象,当有新的 Work 对象被创建了之后会在对应的工作集群中创建 Work 负责的资源对象。
serviceexport controller
serviceexport controller 主要就是处理 serviceexport 资源对象的状态逻辑,将需要被其它集群发现的服务暴露出来。
相关资源对象:ServiceExport
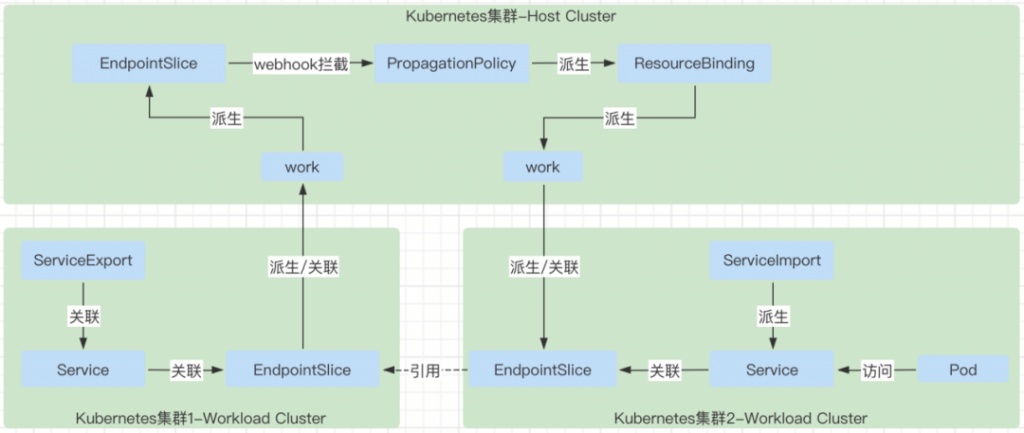
- 当控制平面创建 ServiceExport 对象的时候,会对应的创建出 Work 对象,以及在对应的工作集群中创建出 ServiceExport 对象。
- 查找出 ServiceExport 对象对应的 service 对象的 EndpointSlice 对象,将这些 EndpointSlice 对象封装成 work 对象创建到控制平面中。
- 当在控制平面删除 ServiceExport 对象的时候,会找到对应的 work 对象,将其删除。这里删除的时候也会一起删除由 ServiceExport 关联上报上来的 EndpointSlice 对象对应的 Work 对象。因为查找要删除的 Work 的时候是根据服务名查找的,而 ServiceExport 和 Serivce 对应的 EndpointSlice 的 Work 都是用服务名来创建的,所以查找的时候会一起查找到。
- 当工作集群的 EndpointSlice 发生变化的时候,也会同步去更新控制平面的 EndpointSlice 对象,因为 ServiceExport controller 是 watch 了每一个集群的 ServiceExport 的 add 事件以及 EndpointSlice 的 add 和 update 事件的。只要 EndpointSlice 变化,就会同步到控制平面。这样会触发 PropagationPolicy 关联的对象发生变化,就会触发更新 EndpointSlice 对应的 Work,也就会同步更新 ServiceImport 集群中由于 ServiceImport 而级联出来的 EndpointSlice 了。
endpointslice controller
endpointslice controller 主要根据 serviceexport 资源对象对应到处的 Service,Service 对应的 endpointslice 上报到 Karmada 的控制面。
相关资源对象:EndpointSlice 相关的 Work
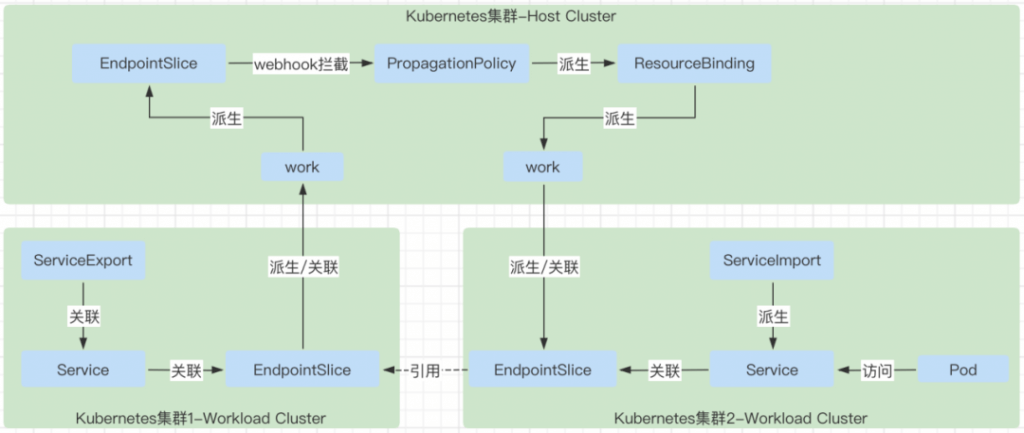
- 负责将 work 中的 manifest 是 EndpointSlice 的 work 中的 EndpointSlice 对象,在 Karmada 控制平面中创建对应的 EndpointSlice 的对象。
- 其中 Karmada 控制平面中的 EndpointSlice 的 namespace 就是和 work 中 manifest 中的 EndpointSlice 的 namespace 一样。但是 Karmada 控制平面中的 EndpointSlice 的 name 不一样,格式为:“imported-<cluster name>-<endpointslice name>”。
serviceimport controller
serviceimport controller 主要负责根据 ServiceExport 暴露出来的 Service,在自己负责的集群中创建对应的 service,注意 service 的名称不是完全一样的,同时在自己负责的集群中也创建对应的 EndpointSlice,这个 EndpointSlice 的数据就是来源于 EndpointSlice controller 中上报到 karmada 控制平面的 EndpointSlice 对象,具体是通过在 karmada-webhook 中给 ServiceImport 的 PropagationPolicy 中增加了 EndpointSlice 的下发能力。
相关资源对象:ServiceImport
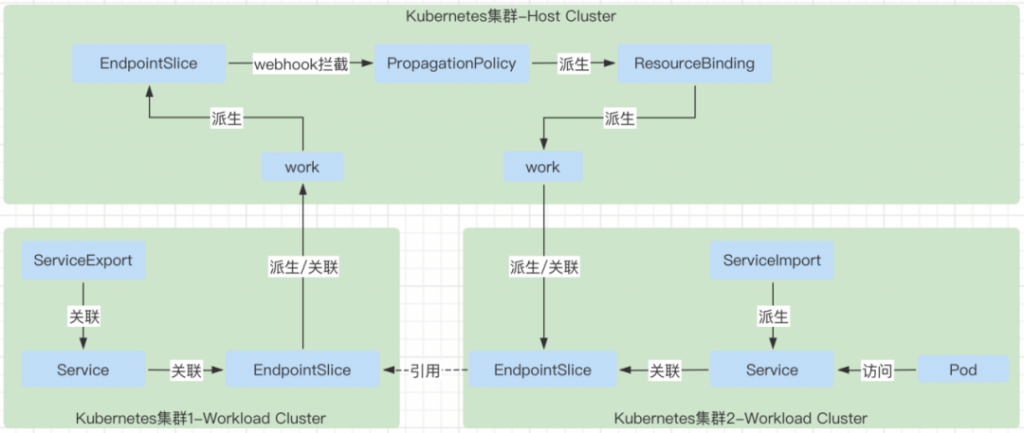
- 根据在 karmada 控制平面中创建的 ServiceImport ,去创建对应的 Service,这个 Service 是创建在 Karmada 控制平面的。
- 如果控制平面中的 ServiceImport,也会删除控制平面中的由这个 ServiceImport 派生出来的 Service。
- 由于 ServiceImport 的 controller 中会在控制平面中创建 Service,同时由于 ServiceExport 的 controller 中,会创建一个被 export 的 Service 的 EndpointSlice 的 work 在控制平面中,这个 work 会被 EndpointSlice controller 控制,同时 EndpointSlice controller 在控制平面中创建对应的 EndpointSlice 对象,EndpointSlice 中的每一个 Endpoint 的 IP 都是 Pod 的 IP 地址。
- 在创建 ServiceImport 需要的 PropagationPolicy 的时候会在 karmada-webhook 中修改 PropagationPolicy 的 resource selector,在其中增加 Service 和 EndpointSlice 的部分,helper.GetFollowedResourceSelectorsWhenMatchServiceImport(policy.Spec.ResourceSelectors)。 最后会随着 detector 和 binding controller 中的逻辑,在对应的集群的 execution 的 space 中创建对应 Service 和 EndpointSlice 的 work,然后由 execution controller 去对应的工作集群去创建真正的资源对象。这样在 ServiceImport 的集群中,就可以通过派生出来的 Service,进行访问远程被 export 出来的服务。前提是两个集群之间的 Pod 网络是互通的。
- 由 ServiceImport 派生出来的 service 的 name 为 :"derived-<service name>"。
hpa controller
hpa controller 主要负责将 Karmada 控制面中创建的 HPA 对象通过创建 Work 的方式下发到对应的集群中。
相关资源对象:HPA
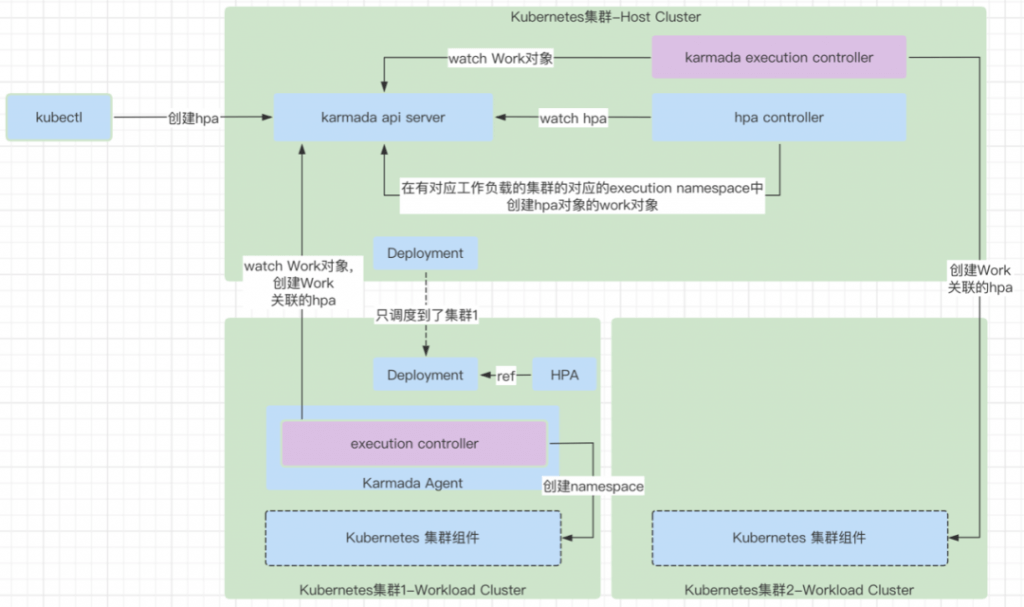
- 首先根据 HPA 的定义,获取需要被 HPA 控制的资源对象对象,这里主要就是指的像 Deployment 这种需要计算资源的对象。
- 根据 HPA 控制的资源对象,去查找这些资源对象对应的 ResourceBinding 的 cr 对象,因为 ResourceBinding 是最终反应 Deployment 被调度到哪些集群的实时的,最终的状态。
- 根据找到的集群,在这些集群中创建每个集群对应的 Work 对象,这个 Work 对象负责的资源对象就是 HPA 对象。
- 通过这样的实现,保证了 HPA 被创建的集群一定是和真正的工作负载是在一个集群中的,保证了 HPA 的正确的调度。
本文为转载文章,贵在分享,版权归原作者及原出处所有,如涉及版权等问题,请及时与我联系。
原文出处:道客船长
原文链接:https://mp.weixin.qq.com/s?__biz=MzA5NTUxNzE4MQ==&mid=2659273922&idx=1&sn=f17630589507999fc0690741c22178b9
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫