

Karmada 概念介绍

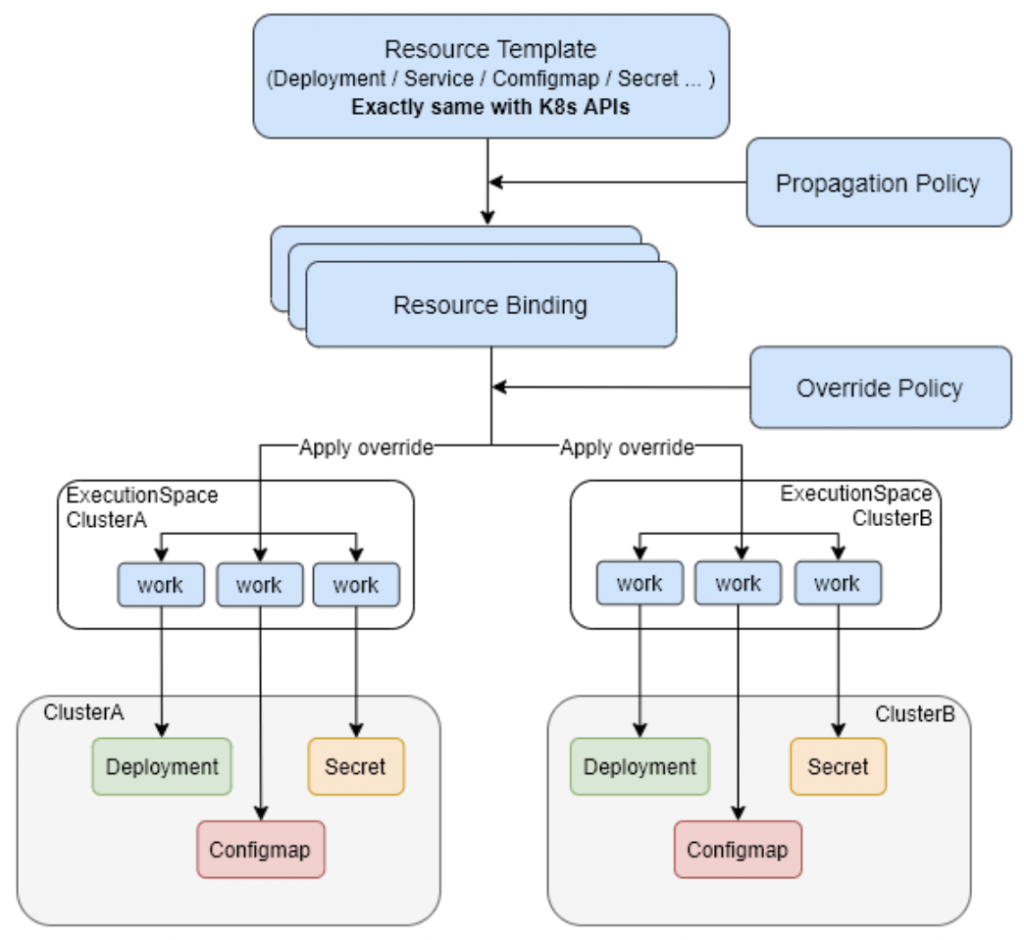

ResourceTemplate
在 Karmada 中没有真正的 crd 类型是 ResourceTemplate,这里的ResourceTemplate 只是对 Karmada 可分发的资源对象的一种抽象,这里的Resource 包含 Kubernetes 中所有支持的资源对象的类型,包括常见的 Deployment,Service,Pod,Ingress,PVC,PV, Job 等等,同时也原生的支持 CRD。
Cluster
Cluster 对象代表一个完整的,单独的一套 Kubernetes 集群,是可用于运行工作负载的集群的抽象和连接配置。在 Karmada 中,集群不仅仅有 spec,还有 status,这个 status 中描述了集群的基本信息,支持的 crd,以及集群的可用物理资源的统计等,用于在后续的调度器中使用这些信息进行调度处理。这些 Cluster 对象会被保存在 karmada-cluster 这个 namespace 中,这个 namespace 的作用有点类似 Kubernetes 的 kube-system,是系统预留的 namespace。
yaml 内容如下:
apiVersion: cluster.karmada.io/v1alpha1
kind: Cluster
metadata:
creationTimestamp: "2022-03-23T23:05:04Z"
finalizers:
- karmada.io/cluster-controller
name: karmada-member1
resourceVersion: "920"
uid: 2873e5a4-79ad-4d7d-9da8-b8cfb4bd107b
spec:
apiEndpoint: https://192.168.31.99:16443
impersonatorSecretRef:
name: karmada-member1-impersonator
namespace: karmada-cluster
secretRef:
name: karmada-member1
namespace: karmada-cluster
syncMode: Push
status:
apiEnablements:
- groupVersion: admissionregistration.k8s.io/v1
resources:
- kind: MutatingWebhookConfiguration
name: mutatingwebhookconfigurations
- kind: ValidatingWebhookConfiguration
name: validatingwebhookconfigurations
- groupVersion: apiextensions.k8s.io/v1
resources:
- kind: CustomResourceDefinition
name: customresourcedefinitions
- groupVersion: apiregistration.k8s.io/v1
resources:
- kind: APIService
name: apiservices
- groupVersion: apps/v1
resources:
- kind: ControllerRevision
name: controllerrevisions
- kind: DaemonSet
name: daemonsets
- kind: Deployment
name: deployments
- kind: ReplicaSet
name: replicasets
- kind: StatefulSet
name: statefulsets
- groupVersion: authentication.k8s.io/v1
resources:
- kind: TokenReview
name: tokenreviews
- groupVersion: authorization.k8s.io/v1
resources:
- kind: LocalSubjectAccessReview
name: localsubjectaccessreviews
- kind: SelfSubjectAccessReview
name: selfsubjectaccessreviews
- kind: SelfSubjectRulesReview
name: selfsubjectrulesreviews
- kind: SubjectAccessReview
name: subjectaccessreviews
- groupVersion: autoscaling/v1
resources:
- kind: HorizontalPodAutoscaler
name: horizontalpodautoscalers
- groupVersion: autoscaling/v2
resources:
- kind: HorizontalPodAutoscaler
name: horizontalpodautoscalers
- groupVersion: autoscaling/v2beta1
resources:
- kind: HorizontalPodAutoscaler
name: horizontalpodautoscalers
- groupVersion: autoscaling/v2beta2
resources:
- kind: HorizontalPodAutoscaler
name: horizontalpodautoscalers
- groupVersion: batch/v1
resources:
- kind: CronJob
name: cronjobs
- kind: Job
name: jobs
- groupVersion: batch/v1beta1
resources:
- kind: CronJob
name: cronjobs
- groupVersion: certificates.k8s.io/v1
resources:
- kind: CertificateSigningRequest
name: certificatesigningrequests
- groupVersion: coordination.k8s.io/v1
resources:
- kind: Lease
name: leases
- groupVersion: discovery.k8s.io/v1
resources:
- kind: EndpointSlice
name: endpointslices
- groupVersion: discovery.k8s.io/v1beta1
resources:
- kind: EndpointSlice
name: endpointslices
- groupVersion: events.k8s.io/v1
resources:
- kind: Event
name: events
- groupVersion: events.k8s.io/v1beta1
resources:
- kind: Event
name: events
- groupVersion: flowcontrol.apiserver.k8s.io/v1beta1
resources:
- kind: FlowSchema
name: flowschemas
- kind: PriorityLevelConfiguration
name: prioritylevelconfigurations
- groupVersion: flowcontrol.apiserver.k8s.io/v1beta2
resources:
- kind: FlowSchema
name: flowschemas
- kind: PriorityLevelConfiguration
name: prioritylevelconfigurations
- groupVersion: networking.k8s.io/v1
resources:
- kind: IngressClass
name: ingressclasses
- kind: Ingress
name: ingresses
- kind: NetworkPolicy
name: networkpolicies
- groupVersion: node.k8s.io/v1
resources:
- kind: RuntimeClass
name: runtimeclasses
- groupVersion: node.k8s.io/v1beta1
resources:
- kind: RuntimeClass
name: runtimeclasses
- groupVersion: policy/v1
resources:
- kind: PodDisruptionBudget
name: poddisruptionbudgets
- groupVersion: policy/v1beta1
resources:
- kind: PodDisruptionBudget
name: poddisruptionbudgets
- kind: PodSecurityPolicy
name: podsecuritypolicies
- groupVersion: rbac.authorization.k8s.io/v1
resources:
- kind: ClusterRoleBinding
name: clusterrolebindings
- kind: ClusterRole
name: clusterroles
- kind: RoleBinding
name: rolebindings
- kind: Role
name: roles
- groupVersion: scheduling.k8s.io/v1
resources:
- kind: PriorityClass
name: priorityclasses
- groupVersion: storage.k8s.io/v1
resources:
- kind: CSIDriver
name: csidrivers
- kind: CSINode
name: csinodes
- kind: StorageClass
name: storageclasses
- kind: VolumeAttachment
name: volumeattachments
- groupVersion: storage.k8s.io/v1beta1
resources:
- kind: CSIStorageCapacity
name: csistoragecapacities
- groupVersion: v1
resources:
- kind: Binding
name: bindings
- kind: ComponentStatus
name: componentstatuses
- kind: ConfigMap
name: configmaps
- kind: Endpoints
name: endpoints
- kind: Event
name: events
- kind: LimitRange
name: limitranges
- kind: Namespace
name: namespaces
- kind: Node
name: nodes
- kind: PersistentVolumeClaim
name: persistentvolumeclaims
- kind: PersistentVolume
name: persistentvolumes
- kind: Pod
name: pods
- kind: PodTemplate
name: podtemplates
- kind: ReplicationController
name: replicationcontrollers
- kind: ResourceQuota
name: resourcequotas
- kind: Secret
name: secrets
- kind: ServiceAccount
name: serviceaccounts
- kind: Service
name: services
conditions:
- lastTransitionTime: "2022-03-23T23:05:05Z"
message: cluster is healthy and ready to accept workloads
reason: ClusterReady
status: "True"
type: Ready
kubernetesVersion: v1.23.4
nodeSummary:
readyNum: 1
totalNum: 1
resourceSummary:
allocatable:
cpu: "2"
ephemeral-storage: 17394Mi
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 3861292Ki
pods: "110"
allocated:
cpu: 950m
memory: 290Mi
pods: "9"
PropagationPolicy/ClusterPropagationPolicy
PropagationPolicy 的作用主要是,为了定义资源对象被下发的策略,如下发到哪些集群,以及下发到这些集群中的需要计算资源的工作负载的副本数应该怎样分配。
PropagationPolicy 是怎样知道自己的策略是作用于哪些资源对象的,这里有一个 resource selector,使用这个选择器去查找和匹配应该被匹配的资源对象,将按照这个 PropagationPolicy 定义的策略进行下发。同时 PropagationPolicy 也是第一个会影响调度器的地方,后续在 ResourceBinding 篇幅里会细讲这个问题。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 1
OverridePolicy
OverridePolicy 的作用是,定义在下发到不同集群中的配置,可以是不一样的,例如不同的集群所对应的镜像仓库的地址是不一样的,那就需要设置在不同集群中的工作负载的镜像地址是不一样,例如在不同的环境下,需要设置不同的环境变量等。
OverridePolicy 的作用时机是在 PropagationPolicy 之后,以及在真正在下发到集群之前,主要处理逻辑是 binding controller 中处理的,会在后续的篇幅中提到。其中可以使用的 override 的能力目前包括 Plaintext,ImageOverrider,CommandOverrider,ArgsOverrider 这几种,用来完成不同集群的差异化配置能力。同样,OverridePolicy 也会通过 resource selector 的机制来匹配到需要查建议配置的资源对象。
apiVersion: policy.karmada.io/v1alpha1
kind: OverridePolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
targetCluster:
clusterNames:
- 10-23-20-93
overriders:
plaintext:
- path: "/spec/template/spec/containers/0/image"
operator: replace
value: "nginx:test"
ResouceBinding/ClusterResouceBinding
ResourceBinding 这个 crd 不是用于给最终用户使用的,而是 Karmada 自身机制工作需要的,主要的用途是说明了某一个资源被绑定到了哪个集群上了,这个和集群绑定的逻辑是在 detector 的 PropagationPolicy 的 controller 中来控制,可以理解成 ResourceBinding 是 PropagationPolicy 派生出来的一个 cr 对象。
同时 Karmada 的调度器的处理对象就是以一个 ResourceBinding 为处理单元,在此基础上来完成资源对象所需要副本数的计算和调度,最终会由 binding controller 完成对 ResourceBinding 的处理,从而生成 Work 对象,同步下发到对应的集群上。
Name: nginx-deployment
Namespace: default
Labels: propagationpolicy.karmada.io/name=nginx-propagation
propagationpolicy.karmada.io/namespace=default
Annotations: policy.karmada.io/applied-placement: {"clusterAffinity":{"clusterNames":["10-23-20-93"]}}
API Version: work.karmada.io/v1alpha1
Kind: ResourceBinding
Metadata:
Creation Timestamp: 2021-11-05T02:52:17Z
Generation: 5
......
Owner References:
API Version: apps/v1
Block Owner Deletion: true
Controller: true
Kind: Deployment
Name: nginx
UID: 967b7a14-044b-4834-a9e4-3321323a6799
Resource Version: 8545931
Self Link: /apis/work.karmada.io/v1alpha1/namespaces/default/resourcebindings/nginx-deployment
UID: 1d0a867d-c386-41c5-8ac7-43e110348918
Spec:
Clusters:
Name: 10-23-20-93
Replica Requirements:
Resource Request:
Cpu: 0
Ephemeral - Storage: 0
Memory: 0
Pods: 0
Replicas: 1
Resource:
API Version: apps/v1
Kind: Deployment
Name: nginx
Namespace: default
Resource Version: 8545930
Status:
Aggregated Status:
Applied: true
Cluster Name: 10-23-20-93
Status:
Available Replicas: 1
Conditions:
Last Transition Time: 2021-11-05T02:52:18Z
Last Update Time: 2021-11-05T02:52:18Z
Message: Deployment has minimum availability.
Reason: MinimumReplicasAvailable
Status: True
Type: Available
Last Transition Time: 2021-11-05T02:52:17Z
Last Update Time: 2021-11-05T02:52:18Z
Message: ReplicaSet "nginx-6c7964bd8f" has successfully progressed.
Reason: NewReplicaSetAvailable
Status: True
Type: Progressing
Observed Generation: 1
Ready Replicas: 1
Replicas: 1
Updated Replicas: 1
Work
Work 这个对象代表了所有资源对象,以及所有资源对象需要下发到多个集群的时候所对应的业务模型。
举例来说,一个 Deployment 需要下发到两个集群中去,那对应到这个 Deployment 的 work 的对象就会有两个,因为 work 是集群单位的对象,主要的作用就是对应和代表一个资源对象在一个集群中的逻辑对象。这个逻辑对象 (work),它保存在控制平面,在后面的 execution controller 中会介绍到 work。work 和 execution 的概念,这里就是 Karmada 在做多集群下发中完成 Host Cluster 和 Workload Cluster 之间真正业务能力的体现。
Name: nginx-687f7fb96f
Namespace: karmada-es-10-23-20-93
Labels: resourcebinding.karmada.io/name=nginx-deployment
resourcebinding.karmada.io/namespace=default
Annotations: policy.karmada.io/applied-overrides:
[{"policyName":"nginx-propagation","overriders":{"plaintext":[{"path":"/spec/template/spec/containers/0/image","operator":"replace","value...
API Version: work.karmada.io/v1alpha1
Kind: Work
Metadata:
Creation Timestamp: 2021-11-03T05:58:49Z
Finalizers:
karmada.io/execution-controller
Generation: 1
......
Spec:
Workload:
Manifests:
API Version: apps/v1
Kind: Deployment
Metadata:
Annotations:
kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"labels":{"app":"nginx"},"name":"nginx","namespace":"default"},"spec":{"replicas":1,"selector":{"matchLabels":{"app":"nginx"}},"template":{"metadata":{"labels":{"app":"nginx"}},"spec":{"containers":[{"image":"10.23.12.61:9120/docker.io/nginx","name":"nginx"}]}}}}
Labels:
App: nginx
propagationpolicy.karmada.io/name: nginx-propagation
propagationpolicy.karmada.io/namespace: default
resourcebinding.karmada.io/name: nginx-deployment
resourcebinding.karmada.io/namespace: default
work.karmada.io/name: nginx-687f7fb96f
work.karmada.io/namespace: karmada-es-10-23-20-93
Name: nginx
Namespace: default
Spec: Progress Deadline Seconds: 600
Replicas: 1
Revision History Limit: 10
Selector:
Match Labels:
App: nginx
Strategy:
Rolling Update:
Max Surge: 25%
Max Unavailable: 25%
Type: RollingUpdate
Template:
Metadata:
Creation Timestamp: <nil>
Labels:
App: nginx
Spec:
Containers:
Image: nginx:test
Image Pull Policy: Always
Name: nginx
Resources:
Termination Message Path: /dev/termination-log
Termination Message Policy: File
Dns Policy: ClusterFirst
Restart Policy: Always
Scheduler Name: default-scheduler
Security Context:
Termination Grace Period Seconds: 30
Status:
Conditions:
Last Transition Time: 2021-11-03T05:58:49Z
Message: Manifest has been successfully applied
Reason: AppliedSuccessful
Status: True
Type: Applied
Manifest Statuses:
Identifier:
Group: apps
Kind: Deployment
Name: nginx
Namespace: default
Ordinal: 0
Resource:
Version: v1
Status:
Conditions:
Last Transition Time: 2021-11-03T05:58:50Z
Last Update Time: 2021-11-03T05:58:50Z
Message: Deployment does not have minimum availability.
Reason: MinimumReplicasUnavailable
Status: False
Type: Available
Last Transition Time: 2021-11-03T05:58:50Z
Last Update Time: 2021-11-03T05:58:50Z
Message: ReplicaSet "nginx-6bd9c997cc" is progressing.
Reason: ReplicaSetUpdated
Status: True
Type: Progressing
Observed Generation: 1
Replicas: 1
Unavailable Replicas: 1
Updated Replicas: 1
Events: <none>
ReplicaSchedulingPolicy
ReplicaSchedulingPolicy 顾名思义就是对副本数分配的一种策略,使用 resource selector 去匹配对应的工作负载,这里的工作负载指的就是 Deployment,Job 之类的。这个和 PropagationPolicy 里的 replicaScheduling 有什么区别?
PropagationPolicy 里的 replicaScheduling 是用于在调度器中使用的,在程序中全称是 ReplicaSchedulingStrategy,也是用于计算副本数分配的。ReplicaSchedulingPolicy 的作用是在调度器没有能计算出每一个集群对应分配的副本数的时候,这个时候 ReplicaSchedulingPolicy 才会生效。在目前的逻辑中,在调度类型是 Failover 类型的时候,会触发 ReplicaSchedulingPolicy 生效,详情会在后续篇幅中提到。
apiVersion: policy.karmada.io/v1alpha1
kind: ReplicaSchedulingPolicy
metadata:
name: foo
namespace: foons
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
namespace: foons
name: deployment-1
totalReplicas: 100
preferences:
staticWeightList:
- targetCluster:
labelSelector:
matchLabels:
location: us
weight: 1
- targetCluster:
labelSelector:
matchLabels:
location: cn
weight: 2
ServiceExport
ServiceExport 的作用是为了解决跨集群服务发现的场景,ServiceExport 不是 Karmada 自己的 CRD,而是 Kubernetes 社区在解决跨集群服务发现的场景下定义的一套 mcs api 规范。
主要的作用就是将某一个集群中,需要被其它集群发现的服务去创建一个 ServiceExport,以此来将这个服务暴露出去。当然不是只有仅仅这个一个 ServiceExport 就可以的,配合下述的ServiceImport 来完成。对于 ServiceExport 和 ServiceImport 的实现,是不同的方案提供商来实现的,Karmada 内置实现了 ServiceExport 和 ServiceImport 的 controller。
kind: Service
apiVersion: v1
metadata:
namespace: demo
name: demo-service
spec:
selector:
app: nginx
ports:
- port: 8080
targetPort: 80
---
kind: ServiceExport
apiVersion: multicluster.x-k8s.io/v1alpha1
metadata:
namespace: demo
name: demo-service
ServiceImport
ServiceImport 的作用是配合 ServiceExport 来完成跨集群的服务发现,要想在某一个集群中去发现另一个集群的服务,除了要在暴露服务的集群中创建 ServiceExport,还要在需要发现和使用这个服务的集群中,创建 ServiceImport 对象,以此来在集群中发现其它集群的服务,和使用这个其它集群的服务,至于在这个集群中是怎样发现的,以及怎样访问的,是不同的方案提供商来实现的,这了会涉及到 Kubernetes 中已有资源对象EndpointSlice。
具体的在 Karmada 中的实现细节,将在后面的 ServiceExport,ServiceImport,EndpointSlice 的 controller 中的篇幅中细讲。
apiVersion: multicluster.k8s.io/v1alpha1
kind: ServiceImport
metadata:
name: my-svc
namespace: my-ns
spec:
ips: - 42.42.42.42
type: "ClusterSetIP"
ports:
- name: http
protocol: TCP
port: 80
sessionAffinity: None
status:
clusters:
- cluster: us-west2-a-my-cluster
EndpointSlice
EndpointSlice 是 Kubernetes 中的已有资源对象的一个。主要作用就是描述了 Service 对应的 Pod 的真正的访问地址以及端口的一些信息。
apiVersion: discovery.k8s.io/v1beta1
kind: EndpointSlice
metadata:
name: imported-my-svc-cluster-b-1
namespace: my-ns
labels:
multicluster.kubernetes.io/source-cluster: us-west2-a-my-cluster
multicluster.kubernetes.io/service-name: my-svc
ownerReferences:
- apiVersion: multicluster.k8s.io/v1alpha1
controller: false
kind: ServiceImport
name: my-svc
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
topology:
topology.kubernetes.io/zone: us-west2-a
Execution Namespace
在 Karmada 的控制平面中,会为每一个被纳管的集群创建一个集群相关的 namespace,这个 namespace 中存放的资源对象是 work。每一个和这个集群相关的 Kubernetes 资源对象都会对应到这个 namespace 下的一个 work。
举例,在 Karmada 的控制平面创建了一个 service 资源对象,同时通过 PropagationPolicy 下发到两个集群中,那在每一个集群对应的 execution namespace 中都会有一个 work 对象对应到当前集群需要负责的 service对象上。
Karmada架构介绍

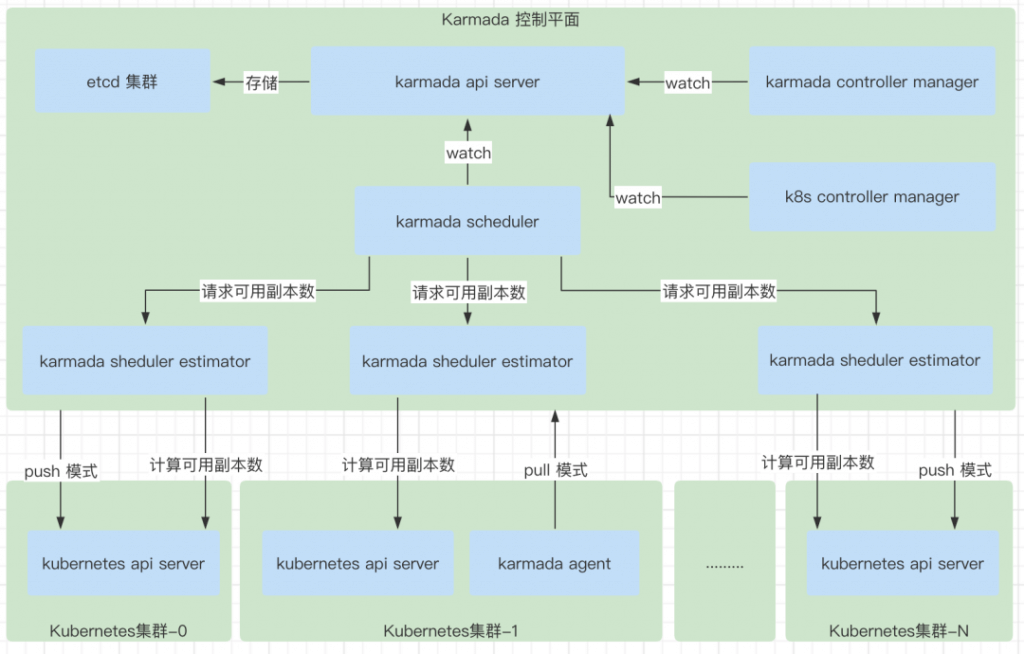
karmadactl
karmadactl 是 Karmada 的命令行程序,主要是方便快速的接入集群,管理集群。
kubectl karmada
kubectl karmada 是 kubectl 的 Karmada 的 plugin 程序,用于 Host Cluster 这个 context 中,使用 kubectl 的 cmd 中可以快速的查看 Karmada 管理的资源对象对象的详细信息。
karmada agent
karmada agent 的作用主要是使用 pull 模式的时候才会需要,这里的 pull 指的是 workload 集群中的 agent 主动去控制平面去 pull 需要下发的资源对象。考虑在云边的场景下,控制面 Host Cluster 运行在公有云,Workload Cluster 运行在私有云的场景下,这个时候是需要安装 agent,每一个集群安装一个 agent 就可以了。也可以在私有环境使用 pull 模式,取决于场景的需要。在安装了 agent 的集群中,这个集群在控制面的工作方式就是 pull 的模式,顾名思义是 agent 主动去控制面去拉取需要处理的 work 对象。
当 agent 在某一个集群启动之后,会在控制平面创建对应的 cluster 对象,同时创建 execution 的 namespace。
启动 4个 controller,包括 cluster status controller, execution controller,work status controller, service export controller 这些 controller,这里有一个需要注意的是在 agent 中启动的这些 controller 在 controller manager 中也会启动,但是区别是 agent 中的 controllers 的关注的事件和 controller manager 中关注的事件是不一样的,通过定义 controller 中的 PredicateFunc 这个参数指定了事件的过滤逻辑,详细请查看 pkg/util/helper/predicate.go 文件。对于需要 agent 处理的事件, 方法名都有一个 “OnAgent” 的后缀。如 “func NewExecutionPredicateOnAgent() predicate.Funcs”。
karmada api server
karmada api server 是和 Kubernetes 集群中的 api server 是一样的角色,负责处理 api 的请求,以及连接到 etcd 数据源持久化元数据,在这个过程中所有的 controllers 和 scheduler 会和 api server 进行通信,类似 Kubernetes 里的 api server 和 controllers 以及 scheduler 的关系。
karmada controller manager
karmada controller manager 主要负责初始化所有相关的 controllers,以及启动所有的 controllers,让所有的 controllers 去工作起来。具体包含的 controller 主要有 cluster controller,cluster status controller,namespace sync controller,propagationpolicy controller,binding controller, execution controller,work status controller,serviceexport controller,endpointslice controller, serviceimport controller,hpa controller。具体每一个 controller 的工作机制将在下面的篇幅中讲解。
karmada Kubernetes controller manager
这里的 controller manager 是使用的 kubernetes 的 controller manager,但是只会用到 gc controller 的能力,用于完成资源对象的垃圾回收工作,其它的能力都没有开启,所以不会因为在 Karmada 创建一个 Deployment 而创建 Pod 出来。
karmada scheduler
这个组件是 Karmada 的调度器,主要是用于完成在资源对象的调度。也是以插件的方式支持调度的扩展能力。其中也会包含 filter 和 score 两个接口。
对于一些需要计算副本比例的资源对象,会首先根据 filter 和 score 选择出一些集群,然后再对需要分配副本的资源对象类型计算每一个集群应该需要分发的副本数。
目前只是支持了 Deployment 和 Job 类型的,对于 StatefulSet 是不支持副本数分配到不到集群的能力。对于非工作负载的资源对象,不会有处理副本数的要求,只会在对应需要被调度的集群,创建一个匹配的资源对象,举例,如在 Karmada 的控制面创建了一个 service 对象,同时 PropagationPolicy 设置了对应希望调度的集群,然后只会在对应的集群中创建一个 service 资源对象。
karmada scheduler estimator
estimator 的组件是负责更加精确的计算副本分配的能力,所以整个工作过程中,只会当被调度处理的资源对象是 Deployment 和 Job 的时候,才会和 estimator 组件进行通信。那 estimator 具体的工作范围是什么?以及有了调度器了,为什么还需要一个 estimator?
在早期的版本中,调度器在计算副本数的分配时,只支持了根据集群状态的资源总和来调度副本数,或者根据静态的权重来固定副本数。
在这个情况下,很有可能因为集群的总体资源是充足的,但是每一台机器的资源不足的,导致最终的 Pod 调度不出去。
为了解决这个问题,引入了 estimator 组件,每一个 estimator 会负责一个独立的集群的可调度副本数的计算。estimator 会根据调度的资源请求,计算出这样的资源规格 (如,pod 的 cpu 是 1core,内存是 2G),在这个集群中,以及这个集群中,所有的节点上可调度的副本数的总和返回回去,在计算每一个节点的可调用副本数的时候,会获取节点的资源使用,根据请求的 pod 的 cpu 和内存去计算,这个主机最多可以运行多少个这样的 pod,这样就可以计算出,单个机器的可用副本数,根据同样的逻辑,对所有的节点都会进行这样的计算,最后得到一个集群真正可以调度的 pod 数量。
这样就可以保证,只要是被调度器计算好的副本数的分配之后,可以在对应的集群中真正的被调度和正常的启动。目前 estimator 只会负责 PropagationPolicy 的 replicaScheduling 中,调度类型为 devided,同时副本分配策略是动态权重的这种调度设置。duplicated 类型,以及静态权重的这种,不会处理。
karmada webhook
webhook 是 kubernetes 中,以及 operator 中常见的组件,主要作用就是对负责的资源对象进行数据格式的验证,以及在没有进入到 etcd 之前进行一些拦截修改数据的能力。
举例,在创建 serviceimport 需要的 PropagationPolicy 的时候会在 webhook 中修改 PropagationPolicy 的 resource selector,在其中增加 service 和 endpointslice 的部分,最后会随着 detector 和 binding controller 中的逻辑,在对应的集群的 execution 的 space 中创建对应 service 和 endpointslice 的 work,然后由 execution controller 去对应的工作集群去创建真正的资源对象,从而在 serviceimport 的集群中创建出 endpointslice 资源对象,来达到跨集群的服务发现的能力。
对社区的思考
从现在的社区来看,Karmada 的玩法更加贴近云原生的玩法,因为被下发的对象是原生的 Kubernetes 对象,包括支持 CRD。同时目前也是在多云支持上,走的最早和最快的一个 CNCF 的开源方案。
以下整理了目前看到需要思考的问题:
- 生产级灾备方案。
- 在创建一个 namespace 资源对象的时候,Karmada 会同步在所有集群创建相同 namespace,如何支持在某一些集群中创建 namespace。
- 如果上层有逻辑 quota ,如果底层无法感知和干预调度,会出现调度结果不一致的问题。
- 怎样支持对 cni 的网络感知,举例,对于支持固定 IP 能力的 cni,如何让调度器感知。
- 现在 operator 非常的多 (statefulset 部署为最佳实践) 但是 Karmada 未做有状态对象的状态收集。
- 老版本 api 的兼容问题。举例在对接 Kubernetes1.15 的时候,出现 crd 的版本不匹配导致的 crd 无法通过 PropagationPolicy 下发到 Workload Cluster 中去。